파이썬 연산에 대해서 배웠다.
그전에 구글 코랩에서 개발을 진행하였다.
구글 코랩에서 엑셀파일을 가져오고 그 파일을 2차원 배열 형태인 데이터 프레임으로 정리해서,
0. 파이썬 및 판다스 이해하기
기본적인 파이썬 문법들에 대해서 공부하였다.
print.
1. 구글 코랩 환경 이해하기
2. 구글 코랩 환경에 엑셀 파일 가져오는 방법
3. 데이터를 정렬하기 위한 과정

Series는 1차원 배열 -> index와 data 존재
DataFrame은 2차원 배열 -> index, column 과 data 존재

간단하게 직접 구현해 보았다.
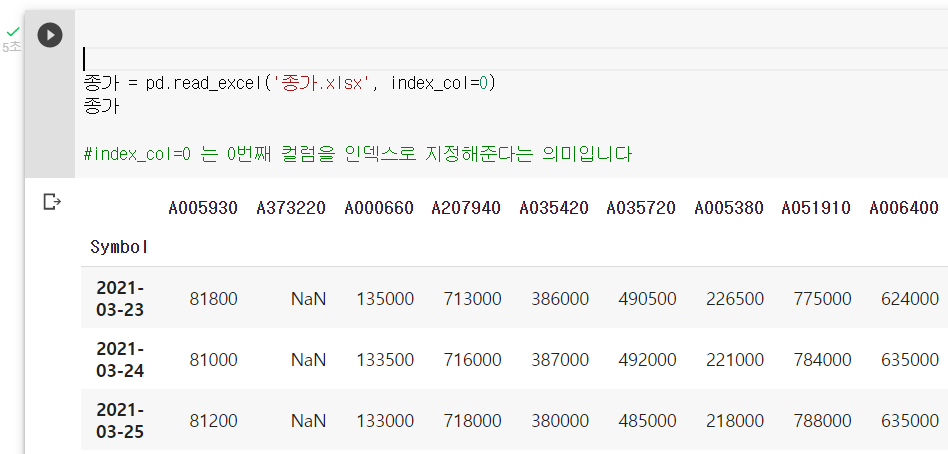
read_excel()의 지정 가능한 옵션 정리
read_excel(filename,
sheet_name = '서울',
header = None,
names = ['일시','평균','최저','최고'],
index_col = None,
usecols = "C:F",
dtype = {'일시':str, '평균':float, '최저':float, '최고':float},
skiprows = 32,
nrows = 28,
na_values = 'nan',
thousands = ',')- sheet_name: 기본값 0. 시트의 인덱스 번호(int) 또는 시트의 이름(문자열)이 들어감. 리스트 값을 넣을 수 있음. None 설정 시 모든 시트 선택
- header: 어느 행(row)에 열(column)의 이름이 있는지 지정. 기본 값은 0으로 첫 번째 줄. None 설정 시 헤더가 없는 것으로 설정되어 첫 번째 줄부터 바로 데이터로 받아옴
- names: header가 None일 경우 열(column)의 이름을 지정해줌
- index_col: 각 행(row)의 이름이 위치한 열(column)을 지정. 기본값은 None
- usecols: 기본값은 None으로 모든 열을 다 불러옴. “A:E”, “A,C,F:H” 와 같이 원하는 열을 선택해 불러올 수 있음
- dtype: 각 열의 데이터 타입을 지정 가능
- skiprows: 엑셀을 읽을 때 첫줄(0)으로 부터 몇 줄을 건너뛸 지 지정
- nrow: 몇 줄을 읽을 지 지정
- na_values: 값이 없는 경우 어떤 str 등으로 넣을 지 지정
- thousands: 돈과 같이 천단위로 쉼표(,)로 구분된 문자를 변환하기 위해 천단위의 구분자가 무엇인지 지정
리스트 인덱싱

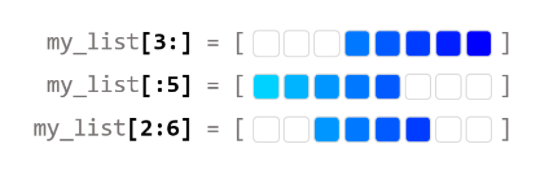

Pandas 행 렬 선택하는 방법.
판다스의 read 함수를 이용해서 데이터를 불러오면, loc을 사용하여 정렬할 수 있다.
1. 행번호(row number)로 선택하는 방법 (.iloc)
2. label이나 조건표현으로 선택하는 방법 (.loc)
https://azanewta.tistory.com/34
iloc, loc를 사용한 행/열 선택법 from Pandas df
Pandas DataFrame에서 특정 행/열을 선택하는 방법은 여러가지가 있습니다. 단연코 Pandas를 사용하면서 이러한 선택의 기로에 많이 놓이게 됩니다. 어떤 방법을 써야될지 혼동이 오는 경우가 참 많죠.
azanewta.tistory.com
1. 행번호(row number)로 선택하는 방법(.iloc)
" 행이든 열이든 숫자로 location을 나타내서 Selecting or indexing 하는 방법입니다."


[python pandas 기초] DataFrame의 속성: index, columns, shape, dtypes 등
파이썬을 이용해서 코딩을 하다 보면 많이 사용하는 라이브러리 중 하나가 바로 판다스입니다. 오늘은 pandas dataframe을 활용할 때 알아두면 도움이 되는 기초 속성 9가지를 알아보겠습니다. 코드
hogni.tistory.com
4.3 데이터프레임 고급 인덱싱 — 데이터 사이언스 스쿨
.ipynb .pdf to have style consistency -->
datascienceschool.net
이 사이트에 인덱싱에 대해서 모두 정리되어있다.
'금융IT > 알고리즘 트레이딩을 위한 파이썬 API 공부' 카테고리의 다른 글
| Dart 부트캠프 알고리즘 트레이딩을 위한 Python 및 Pandas 강의 (0) | 2022.03.25 |
|---|

댓글